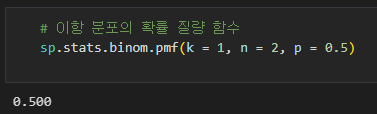
이번에는 신경망의 기본적인 구조를 소개하겠습니다. 그리고 파이썬으로 구현을 하면서 헌형모델과 복잡한 머신러닝을 비교해볼께요! 신경망을 사용하는 예제에서는 붓꽃의 종을 판별하게 만들어보겠습니다. 붓꽃의 꽃받침 길이와 너비를 이용해서 붓꽃의 종류를 알아내는 예측 모델을 만들겠습니다. 입력 벡터, 목표 벡터, 가중치, 편향 통계모델과 머신러닝에서는 같은 뜻이지만 사용하는 용어가 다른 경우가 있습니다. - 독립변수는 머신러닝용어로 입력 벡터라고 합니다. - 종속변수는 목표 벡터라고 합니다. - 계수는 가중치라고 합니다. - 절편은 값이 항상 1인 독립변수로 볼 수 있으며, 편향이라고 합니다. 단순 퍼셉트론 단순 퍼셉트론은 아래 그림처럼 입력 벡터에 가중치(w1,w2,w3)가 반영된 값을 합해서 하나의 출력으로 ..