분산분석은 정규선형모델에서 폭넓게 이용되는 검정 방법입니다.
분산분석(ANOVA)은 통계적으로 그룹 간 차이를 검정하기 위해 사용되는 방법입니다. 일반적으로 분산분석은 다음과 같은 상황에서 필요합니다:
그룹 간 비교: 분산분석은 그룹 간 평균의 차이를 검정하기 위해 사용됩니다. 여러 그룹이 있고 각 그룹 간에 차이가 있는지 확인하고자 할 때 분산분석을 사용할 수 있습니다. 예를 들어, 약을 복용한 여러 그룹의 평균 효과를 비교하거나 교육 수준에 따라 소득의 차이를 비교할 수 있습니다.
요인 간 상호작용 검정: 분산분석은 또한 그룹 간 차이뿐만 아니라 요인 간 상호작용의 존재 여부도 검정할 수 있습니다. 즉, 그룹 간 차이가 통계적으로 유의미한지 뿐만 아니라 그룹 간 차이가 다른 요인(예: 성별, 연령 등)에 따라 어떻게 변화하는지 검정할 수 있습니다.
실험 설계: 분산분석은 실험 설계에 많이 사용됩니다. 실험에서 독립 변수(예: 처리, 조건)의 수준에 따른 종속 변수의 변화를 분석하고자 할 때 분산분석을 사용할 수 있습니다. 예를 들어, 농작물에 다른 비료 처리를 적용하여 수확량을 비교하는 실험에서 분산분석을 사용할 수 있습니다.
요약하면, 분산분석은 그룹 간 차이와 상호작용을 검정하거나 실험 설계에서 독립 변수의 영향력을 분석하는 데 사용됩니다. 따라서 이러한 상황에서 분산분석을 필요로 할 수 있습니다.
분산분석의 귀무가설과 대립가설
- 귀무가설: 수준 간(변수)의 평균값에 차이가 없다.
- 대립가설: 수준 간(변수)의 평균값에 차이가 있다.
필요한 라이브러리 임포트
# 수치 계산에 사용하는 라이브러리
import numpy as np
import pandas as pd
import scipy as sp
from scipy import stats
# 그래프를 그리는 라이브러리
from matplotlib import pyplot as plt
import seaborn as sns
sns.set()
# 통계 모델을 추정하는 라이브러리(워크닝이 나올 수도 있습니다)
import statsmodels.formula.api as smf
import statsmodels.api as sm
# 표시 자릿수 지정
%precision 3
# 그래프를 jupyter Notebook 내에 표시하도록 하기 위한 지정
%matplotlib inline데이터 가져오기
- 이번 예제에는 계산 결과를 보기 쉽게 하기 위해 일부러 작은 데이터를 준비했습니다.

날씨별로 살펴본 매상의 상자그림
- 날씨별 매상의 평균치를 계산해보면, 비오는날은 매상이 적고, 맑은 날은 많으며, 흐린날은 중간인 데이터입니다.

statsmodels를 이용한 분산분석
- 이번 분석에서는 복잡한 군간 제곱합, 군내 제곱합, 군간 평균제곱, 군내 평균제곱, p값, F비를 계산하는 방법은 빼도록 하겠습니다. 이유는 양도 많아지고 가독성이 떨어질뿐더러 사실상 파이썬 라이브러리를 활용하면 굳이 저런 방법을 알고 있지 않더라도 어떻게 해석하는지만 배우면 간단한 코드 한줄로 끝내기 때문입니다.

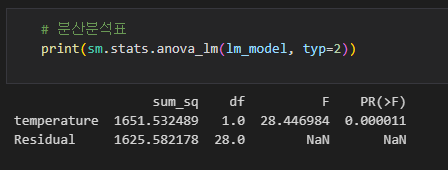
sm.stats.anova_lm 함수의 결과로 출력된 표 형식을 분산분석표라고 합니다.
분산분석표에는
군간과 군내의 편차 제곱합: sum_sq
자유도: df
F비: F
p값: PR(>F)
가 정리되어 있습니다.
간단하게 해석해보자면 p값이 0.05이하가 됐으므로 날씨에 의해 매상이 유의미하게 변화한다고 판단할 수 있습니다.
분산분석에서는 데이터를 효과의 크기와 오차의 크기로 분리합니다. 그리고 각각의 크기를 분산으로 정량화합니다. 효과의 크기를 군간변동, 오차의 크기를 군내변동이라고 부릅니다. 군간 분산과 군내 분산의 비율, 즉 F비를 통계량으로 사용합니다. 모집단이 등분산 정규분포를 따를 때 F비는 F분포를 따른다는 것이 밝혀져 있기 때문에 F분포의 누적분포함수에서 p값을 계산하고, 그 p값이 0.05이하인지 판정합니다.
모델 계수 해석

Intercept (절편):
Intercept는 독립 변수들이 0일 때(모든 더미 변수가 0일 때)의 종속 변수의 예측값을 나타냅니다.
주어진 모델에서 Intercept는 7.0입니다. 이는 다른 독립 변수의 영향을 고려하지 않았을 때 종속 변수의 예측값이 7.0이라는 의미입니다.
weather[T.rainy] (비가 오는 날):
weather 변수의 레벨 중 하나인 "비가 오는 날"을 나타내는 더미 변수입니다.
비가 오는 날에 대한 계수는 -4.0입니다. 이는 "비가 오는 날"이라는 변수가 1일 때, 다른 독립 변수들을 고려하여 종속 변수의 예측값이 4.0만큼 감소한다는 것을 의미합니다. 예를 들어, "비가 오는 날"에 대응하는 그룹의 평균이 전반적으로 4.0 낮을 수 있습니다.
weather[T.sunny] (맑은 날):
weather 변수의 레벨 중 하나인 "맑은 날"을 나타내는 더미 변수입니다.
맑은 날에 대한 계수는 4.0입니다. 이는 "맑은 날"이라는 변수가 1일 때, 다른 독립 변수들을 고려하여 종속 변수의 예측값이 4.0만큼 증가한다는 것을 의미합니다. 예를 들어, "맑은 날"에 대응하는 그룹의 평균이 전반적으로 4.0 높을 수 있습니다.
상자그림 결과와 동일합니다. 비가 오면 매출이 줄어들고, 햇빛이 나는 날에는 매출이 증가하는 것을 확인할 수 있습니다.
모델을 사용해서 오차와 효과 분리하기

anova_model.fittedvalues: 이 적용 결과는 각 수준의 평균값과 일치합니다. 독립변수를 카토게리형 변수로 한 일반선형모델 추측치는 각 수준의 평균값과 일치한다는 것입니다.
anova_model.resid: 적용한 결과값과 실제 데이터의 차이가 잔차입니다. 잔차는 실제 관측값과 모델에 의한 예측값 간의 차이를 나타내며, 모델이 관찰된 데이터에 얼마나 적합한지를 평가하는 데 사용됩니다.
각 잔차 값은 해당 관측값과 모델에 의한 예측값 사이의 차이를 나타냅니다. 예를 들어, 첫 번째 관측값의 잔차는 -1.0입니다. 이는 첫 번째 관측값의 실제 값이 모델에 의해 예측된 값보다 1.0 작다는 것을 의미합니다. 반대로, 두 번째 관측값의 잔차는 1.0으로, 실제 값이 모델에 의해 예측된 값보다 1.0 크다는 것을 나타냅니다.
잔차의 해석은 주로 다음과 같은 측면에서 이루어집니다:
- 잔차의 평균은 0이어야 합니다. 즉, 잔차의 양(양수 또는 음수)이 모델 예측에 대한 편향을 나타내는 것은 아닙니다.
- 잔차의 분포는 정규 분포를 따라야 합니다. 만약 잔차가 비대칭적이거나 이상치를 가지고 있다면 모델의 적합도에 문제가 있을 수 있습니다.
잔차는 모델의 적합도를 평가하고 예측의 정확성을 판단하는 데 사용됩니다. 보통은 잔차의 패턴을 시각화하여 모델의 성능을 평가하고, 이상치나 비선형성 등의 문제를 확인합니다. 잔차를 분석하여 모델의 개선점을 찾고 추가적인 조치를 취할 수 있습니다.
회귀 모델에서의 분산 분석
- 데이터는 앞에 쓴 데이터와 동일한 것을 사용하겠습니다.
2023.05.16 - [programming/파이썬으로 배우는 통계학] - [파이썬/통계] Python 통계 : 정규 선형모델 /연속형 독립변수가 하나인 모델(단순회귀)
[파이썬/통계] Python 통계 : 정규 선형모델 /연속형 독립변수가 하나인 모델(단순회귀)
필요한 라이브러리 임포트 # 수치 계산에 사용하는 라이브러리 import numpy as np import pandas as pd import scipy as sp from scipy import stats # 그래프를 그리는 라이브러리 from matplotlib import pyplot as plt import seabo
jofresh.tistory.com
- 모델의 자유도 = 군간 변동의 자유도
- 군내 변동의 자유도 = 잔차의 자유도
F비 계산

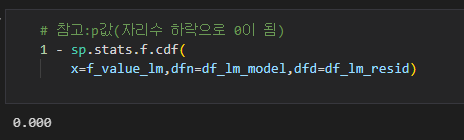
분산분석표
요약하기 함수

출력 상단에 있는 표의 F-statistic이 F비 입니다. 그 밑에 있는 Prob은 분산분석의 p값을 보여줍니다.
또한 독립변수가 1개인 경우에는 계수의 t검정 결과와 분산분석의 결과가 일치합니다. 독립변수가 늘어나면 일치하지 않게 됩니다.
(이번에는 독립변수는 온도 1개 였습니다. 혹시나 하는 마음에 한 번 더 적어둡니다. 독립 변수가 여럿인 경우도 포스팅할께요 :)
'programming > 파이썬으로 배우는 통계학' 카테고리의 다른 글
| [파이썬/통계] Python 통계 : 일반선형모델/ 이항분포 / 푸아송분포 (1) | 2023.05.22 |
|---|---|
| [파이썬/통계] Python 통계 : type 2 anova / 독립변수가 여럿인 모델 / t검정/ 적합한 독립변수 선택 (0) | 2023.05.22 |
| [파이썬/통계] Python 통계 : 정규 선형모델 /연속형 독립변수가 하나인 모델(단순회귀) (0) | 2023.05.16 |
| [파이썬/통계] Python에 의한 기술 통계 : 통계 모델, 모델링에 관하여 (2) | 2023.05.16 |
| [파이썬/통계] Python에 의한 기술 통계 : 분할표검정(카이제곱검정★) (0) | 2023.05.16 |