푸아송 회귀란
확률분포에 푸아송 분포를 사용하고, 링크함수에 로그함수를 사용한 일반선형모델입니다. 독립변수는 여러 개 있어도 상관없고, 연속형과 카테고리형이 혼재되어 있어도 됩니다. WOW~~
※복습
[파이썬/통계] Python 통계 : 일반선형모델 기본/ 로지스틱회귀 모델/null 모델
일반선형모델의 기본 예를 들어'있다, 없다'라는 두 개의 값만 취하는 데이터나 '1개,2개,3개'등 0 이상의 정수만 취하는 데이터가 있다면 모집단분포가 정규분포라고 가정하기에는 무리가 있습
jofresh.tistory.com

필요한 라이브러리 임포트
# 수치 계산에 사용하는 라이브러리
import numpy as np
import pandas as pd
import scipy as sp
from scipy import stats
# 그래프를 그리는 라이브러리
from matplotlib import pyplot as plt
import seaborn as sns
sns.set()
# 통계 모델을 추정하는 라이브러리(워크닝이 나올 수도 있습니다)
import statsmodels.formula.api as smf
import statsmodels.api as sm
# 표시 자릿수 지정
%precision 3
# 그래프를 jupyter Notebook 내에 표시하도록 하기 위한 지정
%matplotlib inline
데이터가져오기
- 이번 데이터는 기온(temperature)에 따른 맥주 판매량(beer_number)입니다.

푸아송 회귀

위 코드는 푸아송회귀 모델을 사용하여 beer 데이터셋에 대해 모델링을 수행하는 내용입니다. 아래는 mod_pois 모델의 요약 정보를 출력하는 코드와 그 결과에 대한 설명입니다:
- smf.glm() 함수를 사용하여 Poisson 회귀 모델을 생성합니다. 모델식은 "beer_number ~ temperature"로 지정되어 있으며, beer 데이터셋을 사용하여 모델을 적합시킵니다.
- family=sm.families.Poisson()은 Poisson 분포를 사용하여 모델을 적합시키겠다는 의미입니다.
- fit() 메서드를 호출하여 모델을 적합시킵니다.
- mod_pois.summary()는 모델의 요약 정보를 출력합니다.
모델 요약 정보에는 다양한 통계적 결과와 모델의 성능 평가 지표가 포함됩니다. 일반적으로, 요약 정보에는 다음과 같은 정보가 포함될 수 있습니다:
모델 요약 통계: 회귀 계수, 표준 오차, t-값, p-값 등과 같은 모델의 회귀 계수에 대한 통계적 추정치가 제공됩니다. 이를 통해 독립 변수와 종속 변수 간의 관계를 파악할 수 있습니다.
설명력: 모델의 설명력을 나타내는 지표들이 제공됩니다. 예를 들어, 결정 계수(R-squared)는 종속 변수의 변동 중 모델이 설명하는 비율을 나타내며, 모델의 적합도를 평가하는데 사용될 수 있습니다.
모델 적합도: 모델의 적합도를 평가하는 지표들이 제공됩니다. 이는 잔차에 대한 정보와 관련된 지표들을 포함할 수 있습니다. 예를 들어, 잔차 분포의 정규성, 이상치 여부 등을 확인할 수 있습니다.
모델 요약 정보를 통해 모델의 성능과 변수들의 통계적인 유의성을 평가할 수 있습니다. 상세한 결과는 요약 정보의 출력을 통해 확인할 수 있습니다.
위 모델 요약 정보는 Poisson 회귀 모델의 결과를 보여줍니다. 아래는 주요 항목에 대한 해석입니다:
- Dep. Variable (종속 변수): "beer_number"는 모델링된 회귀 모델에서 종속 변수로 사용되었습니다. 이 모델에서는 맥주 판매량을 예측하는 데 사용되었음을 나타냅니다.
- No. Observations (관측치 수): 모델링에 사용된 관측치 수는 30개입니다. 데이터셋에서 30개의 관측값이 사용되었음을 의미합니다.
- Model Family (모델 종류): 이 모델은 Poisson 분포를 사용하여 모델링되었습니다. Poisson 분포는 이산적인 이벤트를 모델링하는 데 사용되며, 주로 횟수나 발생 횟수와 같은 카운트 데이터를 다룰 때 유용합니다.
- Method (방법): 모델 적합에는 IRLS (Iteratively Reweighted Least Squares) 방법이 사용되었습니다. IRLS는 일반화된 선형 모델에서 많이 사용되는 최적화 알고리즘입니다.
- Log-Likelihood (로그 우도): 모델의 로그 우도는 -57.672입니다. 로그 우도는 모델이 주어진 데이터에 얼마나 적합한지를 나타내는 지표입니다. 일반적으로 로그 우도가 높을수록 모델이 데이터를 잘 설명한다고 할 수 있습니다.
- Deviance (데비언스): 모델의 데비언스 값은 5.1373입니다. 데비언스는 모델의 적합도를 평가하는 지표로, 모델이 관찰된 데이터와 얼마나 잘 일치하는지를 나타냅니다. 작은 데비언스 값은 모델의 좋은 적합도를 나타냅니다.
- coef (회귀 계수): 회귀 계수는 모델의 독립 변수에 대한 추정치를 나타냅니다. "Intercept"는 절편을 나타내며 0.4476로 추정되었습니다. "temperature"는 독립 변수로서 온도를 나타내며, 0.0761로 추정되었습니다. 이는 온도가 맥주 판매량에 양의 영향을 미치는 것을 의미합니다. 회귀 계수 추정치는 z-값과 함께 제공되며, 이는 각 추정치의 통계적 유의성을 평가하는 데 사용됩니다.
- P>|z| (유의확률): P>|z|는 각 독립 변수의 유의확률을 나타냅니다. 유의확률은 해당 독립 변수가 모델에 유의한 영향을 미치는지를 평가하는 지표로, 작은 값일수록 유의미한 영향을 나타냅니다. "Intercept"의 유의확률은 0.024로, 0.05보다 작으므로 절편은 통계적으로 유의한 영향을 가지고 있다고 할 수 있습니다. "temperature"의 유의확률은 0.000으로, 0.05보다 작으므로 온도는 맥주 판매량에 통계적으로 유의한 영향을 가지고 있다고 할 수 있습니다.
요약하면, 주어진 모델 결과에 따르면 온도 변수는 맥주 판매량에 통계적으로 유의한 양의 영향을 미친다고 해석할 수 있습니다. 절편은 통계적으로 유의한 영향을 가지고 있으며, 모델은 주어진 데이터에 잘 적합되고 관찰된 맥주 판매량을 잘 설명한다는 것을 나타냅니다.
AIC에 의한 모델 선택
AIC를 사용한 모델을 선택합니다. 우선은 Null 모델을 추정합니다.

AIC를 비교하면 기온이라는 독립변수가 들어간 모델의 AIC가 작습니다. 이는 기온 독립변수가 필요하다는 뜻입니다.

조금더 자세히 설명하겠습니다.
위 코드의 출력값은 AIC (Akaike Information Criterion)를 비교하여 Null 모델과 변수가 있는 모델의 상대적인 적합도를 평가하는 것입니다. 아래는 출력값의 해석입니다:
Null모델의 AIC: Null 모델의 AIC 값은 223.363입니다. AIC는 모델의 적합도와 복잡성을 고려하는 지표로, 값이 낮을수록 모델의 적합도가 높다고 해석할 수 있습니다. Null 모델은 독립 변수가 없는 가장 단순한 모델이므로, 변수가 없는 상태에서 종속 변수의 변동을 최대한 설명할 수 있는 기준이 됩니다.
변수가 있는 모델의 AIC: 변수가 있는 모델의 AIC 값은 119.343입니다. Null 모델과 비교하여 변수가 있는 모델의 AIC 값이 더 작으므로, 변수가 있는 모델이 Null 모델보다 데이터를 더 잘 설명한다고 해석할 수 있습니다. 변수가 있는 모델은 종속 변수인 맥주 판매량을 온도로 예측하는 데 사용된 모델입니다.
AIC를 사용하여 모델을 비교할 때, AIC 값이 작은 모델이 데이터를 더 잘 설명한다고 판단할 수 있습니다.
따라서 출력값을 보면 변수가 있는 모델이 Null 모델보다 더 적합한 모델임을 알 수 있습니다.
회귀곡선 그래프

푸아송 회귀의 경우에는 seaborn의 함수로 그릴 수 없기 때문에 추정된 모델의 예측값을 산포도 위에 덧그리도록 작성했습니다.
이런 저런 통계학 함수들로 어렵게 분석을 했지만, 사실 그래프로 그려서 보여주는게 제일 직관적으로 잘 이해가 되긴하네요. 기온이 높을수록 맥주 판매는 상승한다는게 직관적으로 확인됩니다.
회귀계수 해석
링크함수가 항등함수가 아닐 경우에는 획득한 회귀계수의 해석이 바뀝니다.로그함수를 사용한 경우의 계수 해석 방법을 알아보겠습니다.
우선 로그의 특징으로서 덧셈이 곱셈이 된다는 점에 특히 주의할 필요가 있습니다. 일반적인 모델에서는 기온이 1도 오르면 맥주 매출이 X원 증가한다는 해석이 되었지만, 로그함수를 사용하면 1도 오르면 맥주 판매 개수가 Y배가 된다는 해석이 됩니다.
기온이 1도 오르면 맥주 판매개수가 몇 배 되는지 코드로 확인해볼께요.
기온이 1도와 2도일때 판매 개수 예측치의 비율을 보겠습니다.

위 결과는 회귀계수에 EXP를 취한값과 동일합니다.
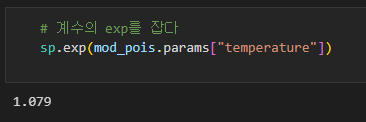
독립변수의 영향이 곱셈이 되는 것은 해석에 있어서 매우 중요하기 때문에 반드시 기억해야합니다.
'programming > 파이썬으로 배우는 통계학' 카테고리의 다른 글
| 사이킷런을 활용한 머신러닝(linear_model) - 릿지 회귀와 라소회귀 최적의 정규화 강도 결정_[파이썬/머신러닝] (0) | 2023.05.29 |
|---|---|
| [파이썬/머신러닝] 통계학과 머신러닝 - 이론적인 부분들 (라소회귀, 릿지회귀) (0) | 2023.05.28 |
| [파이썬/통계] Python 통계 : 일반선형모델 평가(잔차제곱합 구하는 이유) (0) | 2023.05.28 |
| [파이썬/통계] Python 통계 : 일반선형모델 기본/ 로지스틱회귀 모델/null 모델 (1) | 2023.05.22 |
| [파이썬/통계] Python 통계 : 일반선형모델/ 이항분포 / 푸아송분포 (1) | 2023.05.22 |