일반선형모델의 기본
예를 들어'있다, 없다'라는 두 개의 값만 취하는 데이터나 '1개,2개,3개'등 0 이상의 정수만 취하는 데이터가 있다면 모집단분포가 정규분포라고 가정하기에는 무리가 있습니다. 여기서 등장하는 것이 일반선형모델입니다. 일반선형모델을 이용하면 분류 문제와 회귀 문제를 통일성 있게 취급할 수 있습니다.
일반선형모델의 구성요소
1. 모집단이 따르는 확률분포: 일반선형모델은 정규분포나 이항분포, 푸아송 분포 등에 적용할 수 있습니다.
2. 선형예측자: 독립변수를 선형의 관계식으로 표현한 것입니다.
3. 링크함수: 종속변수와 선형예측자를 서로 대응시키기 위해 사용합니다.
링크함수와 확률분포의 대응
| 확률분포 | 링크함수 | 모델명 |
| 정규분포 이항분포 푸아송 분포 |
항등함수 로짓함수 로그함수 |
정규선형모델 로지스틱 회귀 푸아송 회구 |
**항등함수란 f(x)=x가 되는 함수. 아무런 변환도 하지 않는 함수
일반선형모델의 파라미터 추정
일반선형모델에서는 정규분포 이외의 확률분포가 사용되는 경우도 있기 때문에 최대우도법에 의한 파라미터 추정을 합니다. 우도함수가 어떤 형태가 되는지는 따로 설명하겠습니다. 파라미터 추정을 위한 알고리즘으로 반복적인 최소제곱법이 이용 되는 경우가 많습니다.
일반선형모델을 이용한 검정 방법
일반선형모델의 모델 선택 방법을 AIC를 사용한 방법으로 통일합니다. 일반선형모델에서는 회귀계수 t검정을 실시할 수 없습니다. 때문에 이용되는 것이 Wald 검정입니다.
Wald 검정은 샘플사이즈가 클 때 추정값이 정규분포를 따르는 것을 이용한 검정 방법입니다.
일반선형모델에서 분산분석과 같은 해석을 할 수 있는 검정 방법으로 우도비 검정(likelyhood ratio test)이라는 것이 있습니다. 우도비 검정은 모델의 적합도를 비교하는 방법입니다. Type 2 Anova와 같은 해석이 가능한 계산법도 제안되고 있습니다.
로지스틱 회귀
로지스틱 회귀는 확률분포에 이항분포를 사용하고, 링크함수에 로짓함수를 사용한 일반선형모델입니다. 독립변수는 여러 개 있어도 상관없고, 연속형과 카테고리형이 섞여있어도 상관없습니다.
좀 더 자세히 알고 싶다면 아래 접은 글을 클릭해주세요. 구조와 우도함수에 대해서 추가 작성해두었습니다.
로지스틱 회귀(Logistic Regression)는 종속 변수가 이항형(두 개의 범주)인 경우에 사용되는 통계 모델입니다. 로지스틱 회귀는 선형 회귀를 확장하여 로지스틱 함수(또는 시그모이드 함수)를 사용하여 이항형 종속 변수의 확률을 모델링합니다.
로지스틱 회귀의 구조는 다음과 같습니다:
종속 변수:
로지스틱 회귀에서 종속 변수는 이항형(두 개의 범주)이며, 보통 0과 1로 표현됩니다.
이항형 종속 변수의 값은 성공/실패, 양성/음성, 발생/미발생 등과 같이 두 가지 범주를 나타냅니다.
독립 변수:
독립 변수는 종속 변수에 영향을 미치는 요인들로 이루어진 변수들입니다.
독립 변수는 수치형 변수나 범주형 변수일 수 있습니다.
로지스틱 함수 (시그모이드 함수):
로지스틱 회귀에서는 종속 변수의 값을 0부터 1 사이의 확률로 모델링하기 위해 로지스틱 함수(시그모이드 함수)를 사용합니다.
로지스틱 함수는 S자 모양을 가지며, 입력값을 확률로 변환하는 함수입니다.
로지스틱 함수는 아래와 같이 정의됩니다:
P(Y=1|X) = 1 / (1 + exp(-(β₀ + β₁X₁ + β₂X₂ + ... + βₚXₚ)))
회귀 계수:
로지스틱 회귀에서는 독립 변수의 회귀 계수(β, beta)를 추정합니다.
회귀 계수는 로지스틱 함수의 입력 변수들에 대한 영향력을 나타내며, 독립 변수들의 가중치로 해석됩니다.
회귀 계수는 독립 변수의 영향을 나타내는데 사용되며, 양수인 경우 해당 독립 변수가 종속 변수를 양의 방향으로 영향을 주는 것을 의미하고, 음수인 경우 음의 방향으로 영향을 주는 것을 의미합니다.
로지스틱 회귀는 최대 우도 추정(Maximum Likelihood Estimation, MLE)을 사용하여 회귀 계수를 추정하고, 추정된 회귀 계수를 통해 새로운 입력 값에 대한 이항형 종속 변수의 확률을 예측합니다.
로지스틱 회귀의 우도함수(Likelihood function)는 회귀 계수의 값에 따라 주어진 데이터가 발생할 확률을 나타내는 함수입니다. 로지스틱 회귀에서는 이 확률을 최대화하는 방향으로 회귀 계수를 추정합니다.
우도함수는 각 데이터 샘플에 대한 확률을 모두 곱한 것으로 표현됩니다. 이때, 종속 변수의 값을 1과 0으로 나타내고, 로지스틱 함수를 활용하여 각 샘플의 확률을 계산합니다.
주어진 N개의 데이터 샘플이 있을 때, 로지스틱 회귀의 우도함수는 다음과 같이 정의됩니다:
L(β) = Π[ P(Y=1|X) ]^y * [ P(Y=0|X) ]^(1-y)
여기서, P(Y=1|X)는 로지스틱 함수를 통해 계산된 종속 변수가 1일 확률이고, P(Y=0|X)는 종속 변수가 0일 확률입니다. y는 실제 데이터에서의 종속 변수의 값(1 또는 0)을 나타냅니다.
우도함수를 최대화하기 위해 로그 변환을 수행하여 로그 우도함수를 사용하는 것이 일반적입니다. 로그 우도함수는 로그 변환에 의해 곱셈이 덧셈으로 변환되므로 계산이 간편해집니다. 따라서, 로지스틱 회귀의 로그 우도함수는 다음과 같이 정의됩니다:
log L(β) = Σ[ y * log(P(Y=1|X)) + (1-y) * log(P(Y=0|X)) ]
로지스틱 회귀는 이 로그 우도함수를 최대화하는 방향으로 회귀 계수를 추정합니다. 이를 위해 최적화 알고리즘(예: 경사 하강법)을 사용하여 로그 우도함수의 그래디언트를 계산하고, 이를 통해 회귀 계수를 업데이트합니다. 최적화 알고리즘은 로그 우도함수의 값을 최대화하는 회귀 계수를 찾는 데 사용됩니다.
필요한 라이브러리 임포트
# 수치 계산에 사용하는 라이브러리
import numpy as np
import pandas as pd
import scipy as sp
from scipy import stats
# 그래프를 그리는 라이브러리
from matplotlib import pyplot as plt
import seaborn as sns
sns.set()
# 통계 모델을 추정하는 라이브러리(워크닝이 나올 수도 있습니다)
import statsmodels.formula.api as smf
import statsmodels.api as sm
# 표시 자릿수 지정
%precision 3
# 그래프를 jupyter Notebook 내에 표시하도록 하기 위한 지정
%matplotlib inline
데이터가져오기

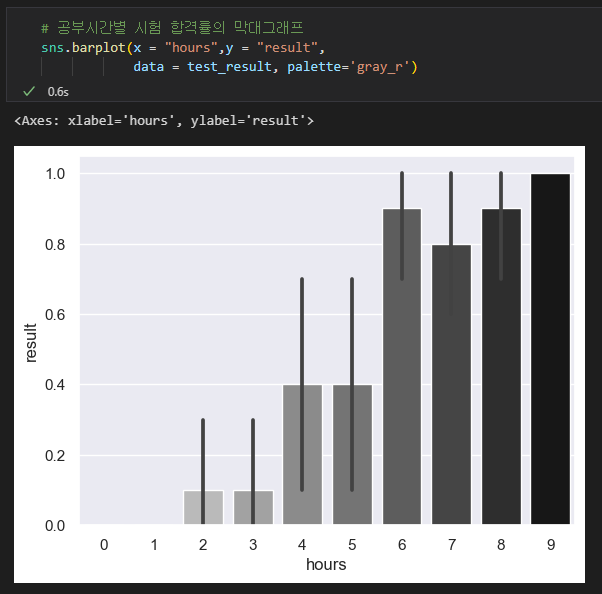
이 그래프를 보면 공부시간이 길어지면 합격률이 높아지는 것처럼 보입니다.
공부시간마다의 합격률을 계산해볼께요.

공부 0시간 = 모두 불합격,
공부 9시간 = 모두 합격한 것을 알 수 있습니다.
로지스틱 회귀 실습
일반선형모델을 추정하는 경우 smf.glm 함수를 사용합니다.

파라미터 지정 설명
첫번째 파라미터 "result ~ hours"는 formula입니다. 정규선형모델과 똑같이 씁니다.
이번에는 종속변수 result, 독립변수를 hours로 지정한 것이 됩니다.
복수의 독립변수가 있는 경우에는 + 기호로 연결하면 됩니다. 이전 포스팅 참조
[파이썬/통계] Python 통계 : type 2 anova / 독립변수가 여럿인 모델 / t검정/ 적합한 독립변수 선택
독립변수가 여럿인 모델 매상 예측 모델에서는 습도, 기온, 날씨, 가격이라는 독립변수를 사용합니다. 날씨는 카테고리형 변수이며, 그 외에는 연속형 변수입니다. 복수의 독립변수를 가지고 있
jofresh.tistory.com
두번째 파라미터에는 확률분포를 지정합니다.
이항분포로 지정했으므로 sm.families.Binomial()이 되었습니다.
푸아송으로 지정하는 경우에는 sm.families.Poission()이 됩니다. (링크함수는 지정되어 있지 않습니다)
이항분포를 지정했을 경우 링크함수를 지정하지 않으면 기본적으로 링크함수에 로짓함수가 지정됩니다.기본 링크함수는 확률분포에 따라 자동으로 바뀝니다. (푸아송 분포를 지정하면 자동으로 로그함수가 됩니다.)
물론 sm.families.Binomial(link = sm.families.links.logit)이라고 명시적으로 로짓함수를 지정할수도 있어요!

Method의 IRLS는 반복적인 최소제곱법의 약자입니다. 내부에서 계산한 반복수가 No.Iterations에 나옵니다.
Deviance와 Pearson chi2라는 지표 2개는 처음나왔습니다. 이는 모델의 적합도를 나타내는 지표입니다.
계수에 대해서는 t검정 대신 Wald 검정 결과가 출력되고 있다는 점을 제외하면 앞서 본 포스팅 결과와 해석하는 방법은 크게 다르지 않습니다. 공부시간의 계수는 양수입니다.
상세 해석 보시려면 접은글 클릭 ▼
해석을 위해 주요 항목들을 하나씩 살펴보겠습니다:
Dep. Variable (종속 변수): "result"
No. Observations (관측값 수): 100
Model Family (모델 분포): Binomial
Link Function (링크 함수): Logit
회귀 계수 (Coefficients):
- Intercept (절편): -4.5587, 표준 오차: 0.901, z-값: -5.061, p-값: 0.000
- hours (독립 변수): 0.9289, 표준 오차: 0.174, z-값: 5.345, p-값: 0.000
해석:
- 절편 (Intercept): 절편은 독립 변수(hours)가 0일 때의 종속 변수(result)의 로그 오즈를 나타냅니다. 이 모델에서는 절편이 -4.5587로 추정되었으며, 통계적으로 유의미한 영향을 가지고 있습니다 (p-값 < 0.05).
- hours (독립 변수): hours 변수는 종속 변수(result)에 대한 로그 오즈의 변화를 나타냅니다. 이 모델에서 hours 변수의 회귀 계수는 0.9289로 추정되었으며, 통계적으로 유의미한 영향을 가지고 있습니다 (p-값 < 0.05). 따라서 hours가 1 증가할 때마다 종속 변수(result)의 로그 오즈는 약 0.9289만큼 증가합니다.
모델의 적합도 및 설명력:
- Log-Likelihood (로그 우도): -34.014, 로그 우도는 모델이 주어진 데이터에 적합한 정도를 나타내는 지표입니다. 높은 로그 우도 값은 모델의 적합도가 더 좋음을 나타냅니다.
- Deviance (탈락도): 68.028, Deviance는 모델의 적합도를 평가하는 지표로, 낮을수록 모델이 데이터를 잘 설명하는 것을 나타냅니다.
- Pseudo R-squared (의사 결정계수): 0.5032, 의사 결정계수는 모델이 종속 변수의 변동성을 얼마나 잘 설명하는지를 나타내는 지표입니다. 0부터 1까지의 값을 가지며, 1에 가까울수록 모델이 데이터를 잘 설명합니다.
이 결과에 따르면, hours 변수는 종속 변수(result)에 통계적으로 유의미한 영향을 가지며, 공부시간이 증가할 수록 합격할 확률이 높아짐을 알 수 있습니다.
모델 선택
AIC를 사용하여 Null 모델과 공부시간이라는 독립변수가 있는 모델 중 어느 쪽이 좋은 모델인지 비교해보겠습니다.
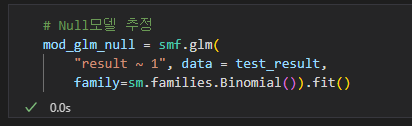

공부시간을 독립변수로 이용한 모델의 AIC가 더 작습니다.공부시간이라는 변수는 합격률을 예측하는데 도움이 된다는 것입니다. 공부시간의 계수가 양수였던 점도 감안하면 공부시간을 늘리면 합격률이 오른다고 판단해도 괜찮을 것 같습니다.
로지스틱 회귀곡선 그래프
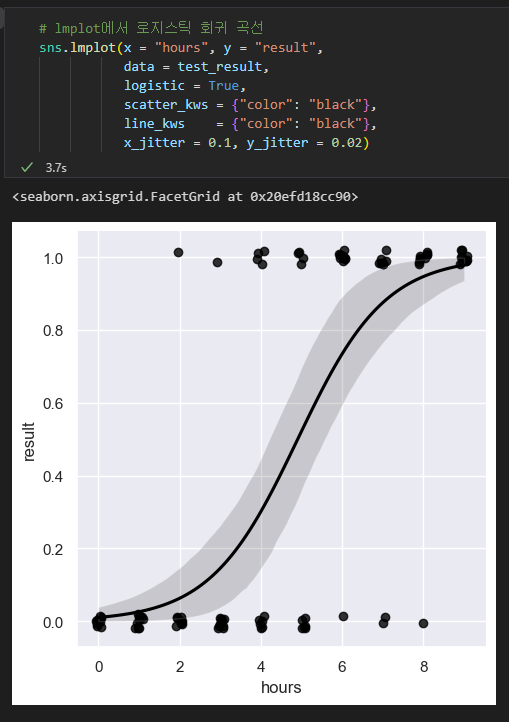
로지스틱 회귀로 구할 수 있었던 이론상의 합격률을 그래프로 나타냈습니다.
가로축에 공부시간, 세로축에 합격여부의 이항확률변수를 지정한 산포도를 그리고, 이론상의 합격률을 겹쳤습니다.
이 그래프는 seaborn의 lmplot 함수에 파라미터를 logistic = True로 넘겨서 그릴 수 있습니다.
성공확률 예측

공부시간으로 시험에 합격할 확률을 예측해보았습니다.
위와 같이 predict 함수를 이용하시면 됩니다.
0시간 공부하면 합격 확률 1%, 9시간 공부하면 확률이 98%까지 올라가네요.
로지스틱 회귀에서 추정된 계수를 해석하기 위해 우선 "odds"와 "odds ratio"에 대해 이해해야 합니다.
Odds (오즈):
- 오즈는 어떤 사건이 발생할 확률과 발생하지 않을 확률의 비율을 나타냅니다.
- 이진 분류 문제에서, 종속 변수의 두 범주(예: 성공/실패, 발생/미발생) 중 하나가 발생할 확률을 오즈로 표현할 수 있습니다.
- 오즈는 [0, 무한대) 범위에 있으며, 1을 기준으로 오즈가 1보다 크면 사건이 발생할 확률이 높고, 1보다 작으면 사건이 발생할 확률이 낮다고 해석할 수 있습니다.
Odds Ratio (오즈 비율):
- 오즈 비율은 두 개의 조건(예: 두 그룹, 두 시점) 간의 오즈의 비율을 의미합니다.
- 오즈 비율은 어떤 변수의 값이 한 단위 증가할 때 종속 변수의 오즈가 몇 배 증가하는지를 나타냅니다.
- 오즈 비율은 종속 변수에 영향을 주는 독립 변수의 효과를 평가하는 데 사용됩니다.
로지스틱 회귀 계수와 오즈 비율 간의 관계는 다음과 같습니다:
- 로지스틱 회귀 계수 (logistic regression coefficient): 로지스틱 회귀 모델에서 독립 변수의 계수는 해당 독립 변수가 종속 변수의 로그 오즈에 미치는 영향을 나타냅니다.
- 오즈 비율 (odds ratio): 로지스틱 회귀 계수를 지수화하여 계산된 값으로, 오즈 비율은 해당 독립 변수의 값이 한 단위 증가할 때 종속 변수의 오즈가 몇 배 증가하는지를 나타냅니다.
- 오즈 비율은 로지스틱 회귀 계수의 지수화로 계산되며, 오즈 비율이 1보다 크면 해당 독립 변수가 종속 변수의 발생 확률을 증가시키는 영향을 가지고 있고, 1보다 작으면 감소시키는 영향을 가지고 있다고 해석할 수 있습니다.
로지스틱 회귀 계수의 부호와 오즈 비율의 관계는 다음과 같습니다:
로지스틱 회귀 계수가 양수인 경우:
독립 변수의 값이 증가할수록 종속 변수의 로그 오즈도 증가합니다.
따라서 오즈 비율은 1보다 크게 됩니다.
이는 독립 변수가 종속 변수의 발생 확률을 증가시키는 영향을 가지고 있다는 의미입니다.
로지스틱 회귀 계수가 음수인 경우:
독립 변수의 값이 증가할수록 종속 변수의 로그 오즈는 감소합니다.
따라서 오즈 비율은 1보다 작아집니다.
이는 독립 변수가 종속 변수의 발생 확률을 감소시키는 영향을 가지고 있다는 의미입니다.
로지스틱 회귀 계수가 0인 경우:
독립 변수와 종속 변수 간에는 선형적인 관계가 없습니다.
따라서 해당 독립 변수는 종속 변수에 영향을 주지 않는 것으로 해석됩니다.
이 경우, 오즈 비율은 1이 됩니다.
즉, 로지스틱 회귀 계수의 부호는 해당 독립 변수가 종속 변수에 어떤 영향을 미치는지를 나타내며, 계수의 크기는 그 영향의 강도를 나타냅니다. 반면, 오즈 비율은 로지스틱 회귀 계수의 지수화로 계산되어 해당 독립 변수의 값이 한 단위 증가할 때 종속 변수의 오즈가 얼마나 변하는지를 나타내는 척도입니다.

'programming > 파이썬으로 배우는 통계학' 카테고리의 다른 글
| [파이썬/통계] Python 통계 : 푸아송 회귀(회귀계수 해석) (0) | 2023.05.28 |
|---|---|
| [파이썬/통계] Python 통계 : 일반선형모델 평가(잔차제곱합 구하는 이유) (0) | 2023.05.28 |
| [파이썬/통계] Python 통계 : 일반선형모델/ 이항분포 / 푸아송분포 (1) | 2023.05.22 |
| [파이썬/통계] Python 통계 : type 2 anova / 독립변수가 여럿인 모델 / t검정/ 적합한 독립변수 선택 (0) | 2023.05.22 |
| [파이썬/통계] Python 통계 : 분산분석/회귀모델의 분산분석 / statsmodels를 이용한 분산분석 (0) | 2023.05.22 |