필요한 라이브러리 임포트
# 수치 계산에 사용하는 라이브러리입니다.
import numpy as np
import pandas as pd
import scipy as sp
from scipy import stats
# 그래프를 그리는 라이브러리입니다.
from matplotlib import pyplot as plt
import seaborn as sns
sns.set()
# 표시 자리수 지정입니다.
%precision 3
# 그래프를 jupyter Notebook 내에 표시하도록 하기 위한 지정입니다.
%matplotlib inline#평균 4,표준 편차 0.8의 정규 분포를 모두 사용
population = stats.norm(loc = 4, scale = 0.8)표본 평균을 몇 번이나 계산해 보다
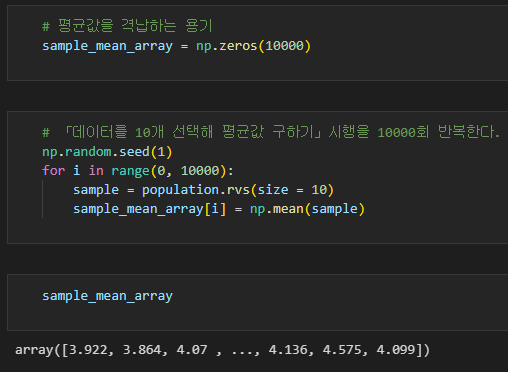
- 이전 시간에서 언급한 함수에 대해서는 간단하게 주석만 달겠습니다. (like np.random.seed(1))
- sample_mean_array는 10000개의 원소를 가진 1차원 배열입니다. 각 원소는 10개의 데이터를 사용하여 계산한 표본평균값을 저장합니다. 이 배열은 나중에 히스토그램을 그리거나 통계량을 계산하는 등의 용도로 사용될 수 있습니다.
표본 평균의 평균값은 모평균에 가깝다.

샘플 크기가 크면 표본 평균은 모평균에 가깝다.

10부터 100100까지 100단계씩 크기가 증가하는 표본을 추출하여 그 표본들의 평균을 계산하여 '표본 평균'을 계산하고 그 결과를 저장하고, 이를 통해 표본 크기가 증가할수록 표본 평균이 모평균인 4에 수렴해 가는 경향을 그래프로 시각화하는 코드입니다.
표본 평균을 여러 번 계산하는 함수를 만들다

위 코드는 모집단에서 크기가 size인 표본을 반복해서 추출하고, 추출한 표본에서 평균을 계산하는 함수 calc_sample_mean을 정의합니다.
이 함수를 이용하여 size=10인 표본을 10000회 추출하여 각각의 표본 평균을 계산하고, 이 표본 평균들의 평균값을 계산한 결과는 4.004입니다. 즉, 모집단의 평균이 4와 비슷한 것을 확인할 수 있습니다.
샘플 크기를 바꿨을 때 표본 평균 분포
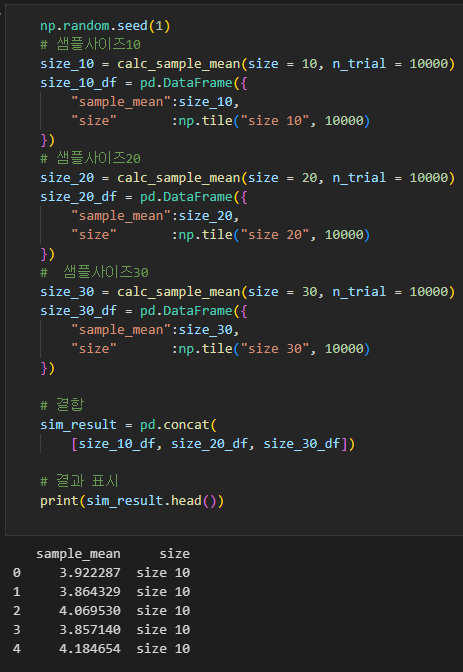
이 코드는 표본 크기가 10, 20, 30일 때의 시뮬레이션 결과를 비교하는 코드입니다.
먼저 calc_sample_mean 함수를 사용하여 표본 크기가 각각 10, 20, 30일 때 10000회의 시뮬레이션 결과를 각각 size_10, size_20, size_30에 저장합니다.
이후 각 결과를 DataFrame으로 변환하고, np.tile 함수를 사용하여 size 열을 추가합니다. 그리고 pd.concat 함수를 사용하여 세 개의 데이터프레임을 합쳐서 sim_result에 저장합니다.
마지막으로 print(sim_result.head())를 사용하여 sim_result의 처음 5행을 출력합니다.

위 코드는 샘플사이즈에 따른 분포를 바이올린플롯으로 시각화하였습니다. 샘플사이즈가 클수록 꼬리가 줄어드는 것을 확인할 수 있습니다. 즉, 표본의 크기가 클수록 모평균과 가까워진다는 것을 확인할 수 있습니다.
표본 평균의 표준 편차는 모표준 편차보다 작아진다

해당 코드는 샘플 크기가 2부터 100까지 2씩 증가하면서 표본 평균의 표준편차를 구하는 코드입니다.
size_array : 샘플 크기를 2부터 100까지 2씩 증가시켜 저장한 배열
sample_mean_std_array : 샘플 크기별 표본 평균의 표준편차를 저장하기 위한 빈 배열
calc_sample_mean 함수 : 이전에 구현한 표본 평균 계산 함수입니다.
for 문을 통해 샘플 크기를 2부터 100까지 2씩 증가시키면서 calc_sample_mean 함수를 이용해 총 100번의 시행을 진행합니다.
각 시행마다 계산된 표본 평균의 표준편차를 sample_mean_std_array 배열에 저장합니다.
마지막으로 plt.plot 함수를 이용하여 샘플 크기에 따른 표본 평균의 표준편차를 시각화합니다. x축은 샘플 크기, y축은 표본 평균의 표준편차 값입니다.
'programming > 파이썬으로 배우는 통계학' 카테고리의 다른 글
| [파이썬/통계] Python에 의한 기술 통계 : 추정 (0) | 2023.05.06 |
|---|---|
| [파이썬/통계] Python에 의한 기술 통계 :정규 분포와 그 응용(확률밀도,t분포,누적분포함수,하측확률,퍼센트포인트) (0) | 2023.05.06 |
| [파이썬/통계] Python에 의한 기술 통계 : 모집단의 표본 추출 시뮬레이션 (0) | 2023.05.06 |
| [파이썬/통계] Python에 의한 기술 통계 : matplotlib·seaborn에 의한 데이터 가시화 (0) | 2023.05.05 |
| [파이썬/통계] Python에 의한 기술 통계 : 다변량 데이터와 pandas 데이터 프레임 (0) | 2023.05.05 |