오늘은 인공지능 알고리즘 중 지도 학습 중 분류 알고리즘에 속하는 SVM에 대하여 알아보자!
아래는 예제에 활용할 데이터이며, 아래는 펭귄의 종, 서식지, 부리의길이, 부리의 두께, 물갈퀴의 길이, 체중, 성별이 담겨져있다.
데이터 불러오기
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
import seaborn as sns
#펭귄 데이터 불러오기
df = pd.read_csv("파일의경로/penguins.csv")
sns.violinplot(x="species", y="body_mass_g", hue="sex", data=df, split=True)
데이터 전처리
결측치가 몇 개인지 파악하고 dropna()로 제거해서 결측치를 없애야 한다.

결측치가 있는 부분을 날리고, 성별의 경우는 'unknow'을 넣어주었다.

위와 같이 하면 결측치 처리가 완료된다.

그리고 학습하기 알맞은 형태로 데이터를 전처리 해줘야 한다.
숫자가 아닌 문자로 이루어진 데이터는 학습을 위해 숫자로 라벨링 해준다.
map() 함수 사용
df['species'] = df['species'].map({"Adelie":0, "Gentoo":1, "Chinstrap":2})
df['island'] = df['island'].map({"Biscoe":0, "Dream":1, "Torgersen":2})
df['sex'] = df['sex'].map({"male":0, "female":1, "unknow":2})

#종속변수와 독립변수로 나누어주고, 8:2 비율로 훈련/테스트 데이터로 분리한다.
#펭귄의 종을 분류할 것이니 종을 Y에
#나머지를 X에 담아준다.
#하지만 불필요한 서식지는 제외하고 나머지 데이터만 담아준다.
dataset = df.values
X = dataset[ : , 2:]
Y = dataset[ : , 0]
X = np.asarray(X)
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=3)
SVM 모델 학습하기
사이킷런에서 제공하는 SVM 알고리즘을 불러서 훈련 데이터로 학습시킨다.
SVM 알고리즘의 핵심은 벡터 경계인 선을 찾는 것인데 부리의 길이, 부리의 두께, 물갈퀴의 길이, 체중, 성별 등 속성의 개수가 늘어날수록 선의 차원도 늘어난다. 차원이 늘어날수록 계산량이 증가하는 부작용이 생기고 이를 해결해주는 것이 '커널 함수'이다.
커널 함수는 분류를 위한 경계를 찾기 위해 적절한 형태로 변환해 계산량 증가를 막아 준다. 커널은 선형과 비선형을 많이 사용한다. 선형 분류가 효율적이고 잘 작동하지만 작동하지 않을 경우 비선형으로 분류한다.
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=3)
import sklearn.svm as svm
svm_model = svm.SVC(kernel = 'linear')
svm_model.fit(X_train, Y_train)
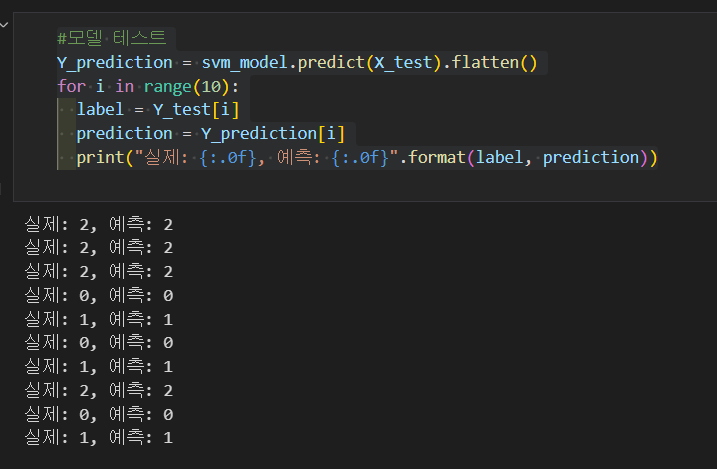
학습이 끝난 SVM모델의 정확도를 보니 100%가 나왔다.

모델 테스트를 10번했는데 10번 모두 일치한다.
이번에도 혼동 행렬과 구체적인 정밀도를 살펴보자. SVM 역시 0번을 예측한 정밀도(precision)가 다른 종 분류보다 낮지만 정밀도는 94%이고, 나머지 두 종의 분류 정밀도는 100%로 평균보다 높은 정밀도로 분류하였다.

다항 분류 딥러닝 모델 학습
다항 분류 딥러닝은 훈련 데이터로 학습을 끝마치면 각각 카테고리로 분류 예측 정도를 나타내는 벡터값이 출력된다. 그 섹가지 벡터값 중에서 가장 큰 값이 있는 카테고리로 분류하는 것이다. 그러기 위해서는 독립 변수 값이 0이나 1,2와 같은 값이 아닌 3개의 가중치를 갖니 리스트 형태이어야 한다.
처음에는 펭귄의 종을 아델리 = 0, 젠투 = 1, 턱끈 = 2 로 라벨링 해주었지만, 이번에는 아델리 = [1,0,0], 젠투 = [0,1,0], 턱끈=[0,0,1]로 변환해준다. 이처럼 0으로 이루어진 벡터에 유일한 1로 해당 데이터를 분류하는 것을 '원-핫 인코딩'이라고 한다.
#원-핫 인코딩
from keras.utils import np_utils
Y_encoded = np_utils.to_categorical(Y)
Y= np.asarray(Y_encoded)
Y[0]
원-핫 인코딩을 적용한 Y데이터를 포함해 다시 훈련/테스트 데이터로 나누어주고 딥러닝 모델을 만든다.
훈련데이터가 200여개로 많지 않으므로 은닉층 없이 입력층과 출력층만으로 구성한다.
input_dim에 속성 개수를 넣고이와 연관해서 인공신경세포 개수를 설정한다. 각 카테고리 분류 정도를 나타나게 하는 활성화 함수가 'softmax'함수이다. 따라서 이항 분류와 다르게 다항 분류 딥러닝 모델은 마지막 출력층의 인공신경세포 개수를 카테고리수로 넣고 활성화 함수를 softmax함수로 설정해야 한다.
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=3)
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
tf.random.set_seed(3)
model = Sequential()
model.add(Dense(15, input_dim=5, activation='relu'))
model.add(Dense(3, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(X_train, Y_train, batch_size=10, epochs=200)
테스트 결과 오차가 0.24 / 정확도가 92.25%가 나왔다. 정확도가 높은 편이지만 SVM 알고리즘으로 학습한 모델보다는 다소 떨어진다.

마지막으로 predict()함수로 나온 예측값과 실제값을 비교해 보면 실제값이 [1,0,0]인 아델리 펭귄의 데이터 예측 결과 아델리 펭귄으로 분류하는 벡터값이 9.69로 가장 높았다.
이렇게 다항 분류는 학습 후 카테고리별 분류 정도 벡터값을 출력하고 가장 큰 벡터값으로 분류한다!

'programming > Python' 카테고리의 다른 글
| [파이썬/머신러닝] 비지도 학습 군집의 개념 (0) | 2024.02.04 |
|---|---|
| [파이썬/머신러닝] 선형 커널을 가진 SVM분류 모델을 만들고 시각화하는 예제 (0) | 2024.02.04 |
| [파이썬] st.text_input으로 텍스트 입력하기 (0) | 2023.12.29 |
| [파이썬] streamlit의 tabs&columns 기능활용하기 (0) | 2023.12.28 |
| [파이썬] streamlit의 slider 이용해서 위젯 만들기 (0) | 2023.12.28 |